Data Import
Subsetting a single column using the column name as an attribute
To subset a single column from the Boston Housing Prices dataset, you can use the DataFrame's column name as an attribute or index. Let's assume you have already imported the required libraries and created the DataFrame boston_df.
Using the DataFrame's Column Name as an Attribute:

If you need a DataFrame with only one column, you can use double brackets to keep it as a DataFrame:

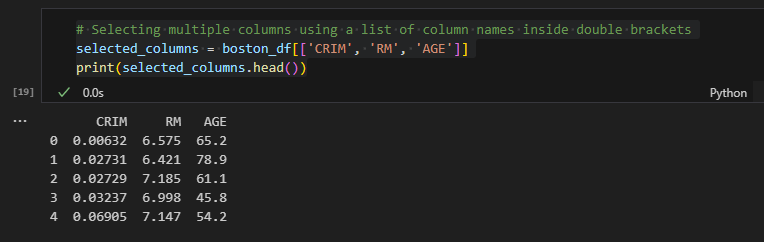
Selecting multiple columns using a list of column names inside double brackets
To select multiple columns from a DataFrame in Python using Pandas, you can use a list of column names inside double brackets [[...]]. Here's how you can do it with the Boston Housing Prices dataset:
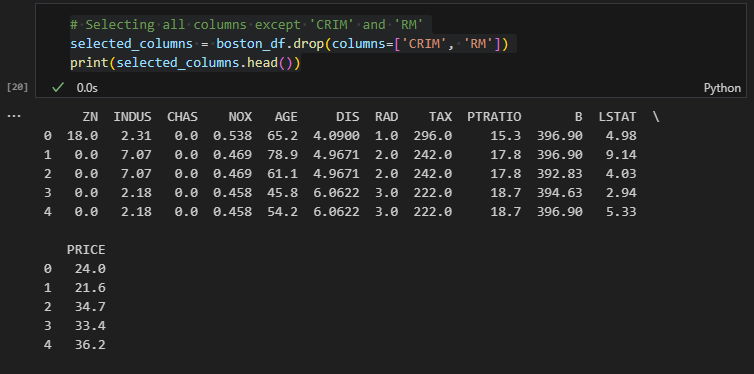
To select all columns except 'CRIM' and 'RM', you can use:
Selecting a single row using a filter (condition)
To select a single row from a DataFrame using filters, you can use boolean indexing. Boolean indexing allows you to filter rows based on certain conditions and retrieve rows that satisfy those conditions. Here's how you can do it with the Boston Housing Prices dataset:

Keep in mind that if multiple rows satisfy the condition, all those rows will be included in the resulting DataFrame. If you are interested in only the first row that satisfies the condition, you can use the .iloc[] attribute:

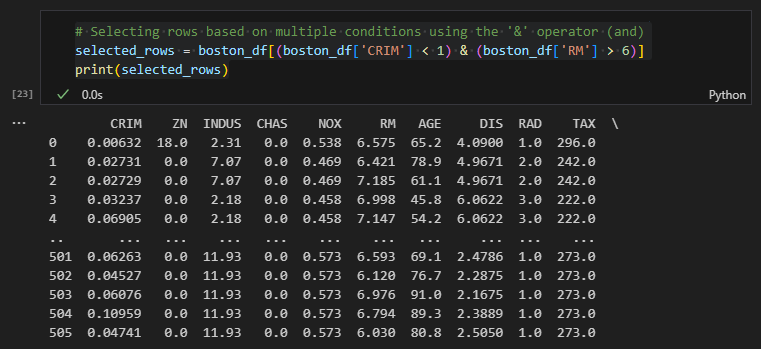
Selecting rows based on multiple conditions using the '&' operator
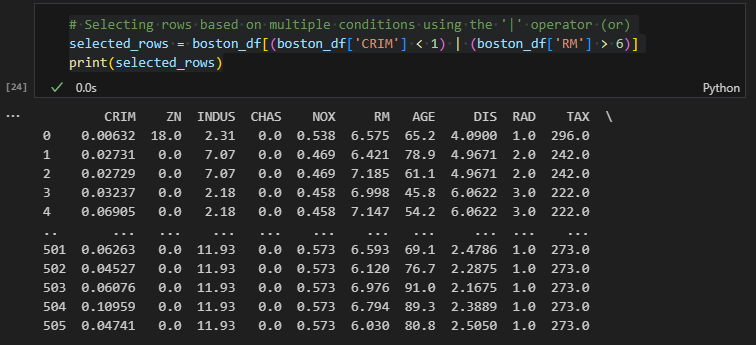
You can also use the | operator to combine conditions with an "or" relationship. For example, to select rows where either the value of the 'CRIM' column is less than 1 or the value of the 'RM' column is greater than 6:
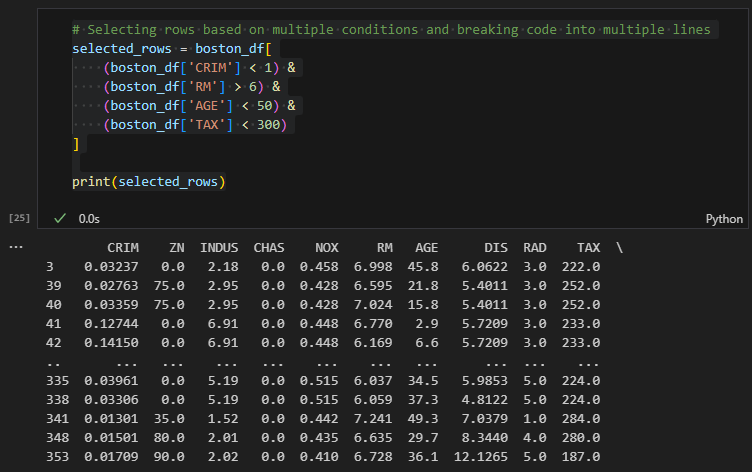
Now, let's select rows based on more than three conditions, and use proper line breaks for code readability:
In this example, we used the & operator to combine four conditions: boston_df['CRIM'] < 1, boston_df['RM'] > 6, boston_df['AGE'] < 50, and boston_df['TAX'] < 300. We grouped each condition inside parentheses to make the code more readable. The backslash \ is used to break the code into multiple lines. By doing this, the code is easier to read and understand.
The key conventions to remember when breaking lines are:
- Use parentheses for grouping conditions together.
- Use the & or | operators to combine conditions.
- Place each condition on a new line after the & or | operator.
- End the line with a backslash \ to indicate that the code continues on the next line.
- Ensure proper indentation for clarity.
This way, you can maintain code readability and make your code more maintainable, especially when dealing with complex conditions involving many columns. Breaking lines in a readable manner helps other developers (and even yourself) to understand the logic of the filtering conditions without having to scroll horizontally.
Selecting rows based on multiple conditions and breaking code into multiple lines
Let's put together the code for selecting multiple columns and rows using the Boston Housing Prices dataset. We'll use both multiple conditions and select specific columns. First, I'll show you how to select the desired columns, and then I'll demonstrate how to add conditions for row selection.
Let's use .loc() and see the difference.
https://ai-fin-tech.tistory.com/entry/Complete-Usage-of-loc-and-iloc-with-pandas
Complete Usage of loc and iloc with pandas
Data Import import pandas as pd from sklearn.datasets import load_boston # Load the Boston Housing Prices dataset boston = load_boston() boston_df = pd.DataFrame(boston.data, columns=boston.feature_names) boston_df['PRICE'] = boston.target A complete usage
ai-fin-tech.tistory.com
'Tech > Python' 카테고리의 다른 글
| pandas - Subsetting Rows with Categorical Variables (1) | 2023.07.30 |
|---|---|
| pandas - Complete Usage of loc and iloc (1) | 2023.07.30 |
| pandas - Sorting DataFrame (1) | 2023.07.30 |
| pandas - Basic DataFrame Inspection (1) | 2023.07.30 |
| pandas - Data Import (1) | 2023.07.30 |




댓글